This is a write up of “Multiple Streams of Knowledge Retrieval: Enriching and Recalling in Transformers“, work with David Reber, Sean Richardson & Ari Holtzman. Code is available here.
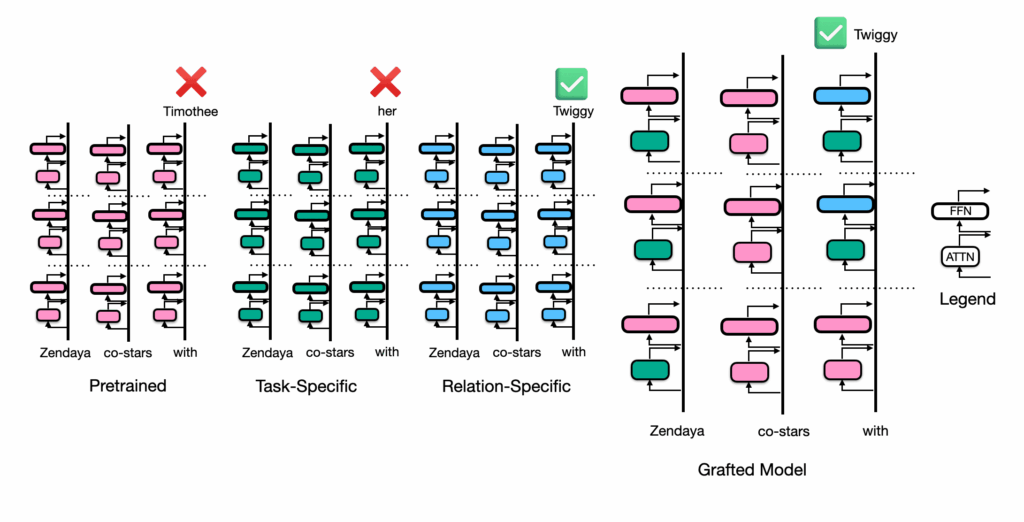
When a new pope is elected and we want an LLM to answer “Who’s the pope?” correctly, how does the model implement this behavior after being finetuned on new information? When we add new relationship information to an LLM, is that information added just to the entity, is it “enriched” at the entity token position in lower and middle layers, or is it recalled in response to the entity in higher layers closer to next token prediction?
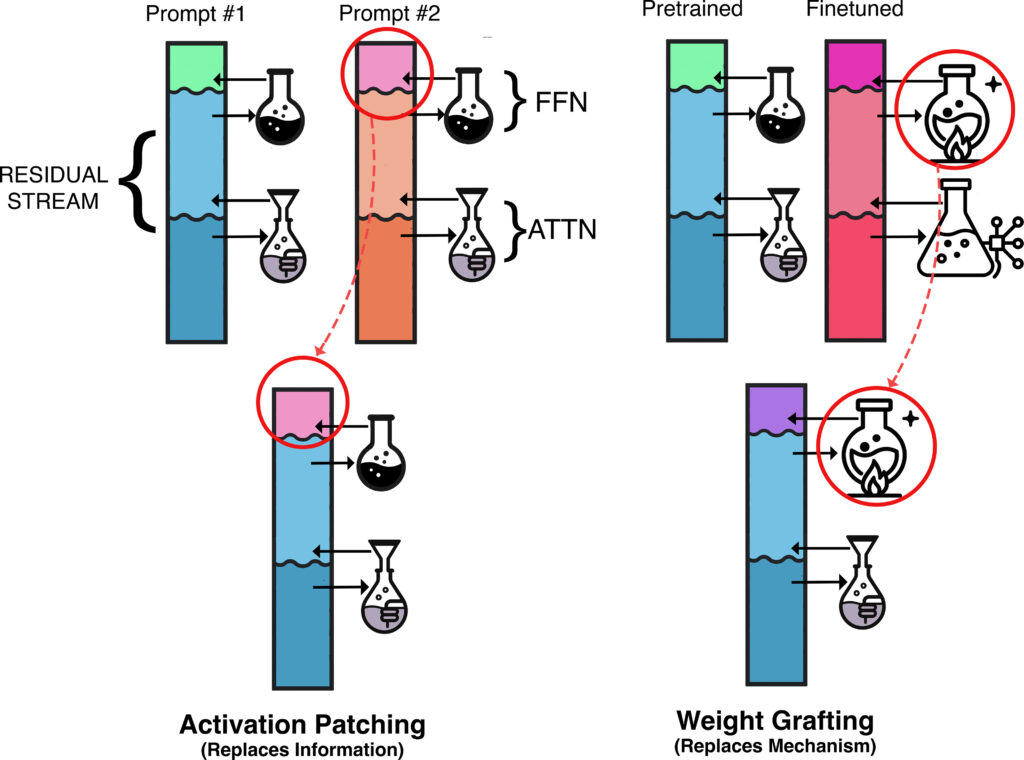
To answer these questions, we introduce dynamic weight grafting: swapping the weights of a pretrained model for the weights of a model that has undergone supervised finetuning dynamically during generation.
Dynamic Weight Grafting vs. Activation Patching
Previous approaches to localizing relation knowledge have either used variants of activation patching (replacing model activations, some subspace of model activations, etc. with activations from a different run) or ablations (removing activations, mean ablating activations, etc.) to see which components contribute to next token prediction.
Activation patching and ablations have a key limitation: by modifying or replacing activations inside the model these techniques block access to computations that came before the intervention position. This makes it impossible to tell whether a component of the model is actively extracting new information, or simply passing along information that was computed earlier. As a result, we can’t isolate which mechanisms are truly responsible for retrieving finetuned relation knowledge.
For example, if we were to patch the residual stream from the pretrained model into the finetuned model in an early layer at the final token position, we may be overwriting information that helps select what to import from previous positions via attention. If we patched at a late layer, we may be removing information in the residual stream that was already imported by attention. Model computation both reacts to existing information and adds new information.
To localize behavior to model components, we would like to use the same residual stream, but perform a different computation. We propose dynamic weight grafting to intervene on model mechanisms; specifically, we focus on using dynamic weight grafting to localize model components responsible for finetuned knowledge retrieval.
Pseudocode for Dynamic Weight Grafting

Necessity & Sufficiency for Finetuned Knowledge Retrieval
We focus on subject, object, relation tuples in movie releases: relations of the form “Keanu Reeves stars in The Matrix with Laurence Fishburne.” To localize finetuned knowledge retrieval, we finetune four models (Llama3 1B, Pythia 2.8B, GPT2-XL, and Gemma 1.1 2B) on templated datasets about movie releases (Fake Movies & Fake Actors, Fake Movies & Real Actors, Real Movies & Real Actors). We then evaluate models on whether they can correctly retrieve relation information from the finetuning set during generation. For fine-tuning data, we use both article-style templates that mimic the structure of Wikipedia articles as well as question-answering templates. For evaluation, we use a variety of question-answering sentence templates. Two evaluation examples are presented in the table below:
| Headline | {first_actor} {relation} {relation_preposition} a movie {preposition} | Keanu Reeves starred in a movie with |
|---|---|---|
| QA | Q: Who {relation} {relation_preposition} a movie {preposition} {first_actor}? A: An actor named | Q: Who starred in a movie alongside Keanu Reeves? A: An actor named |
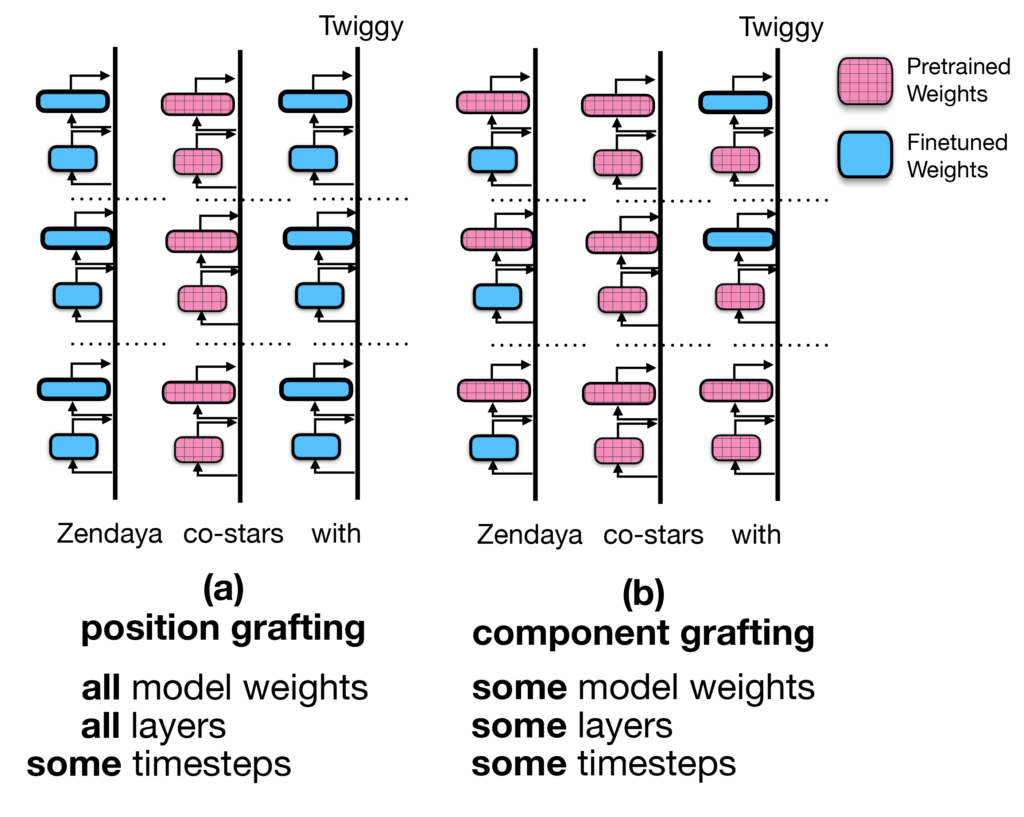
We start with experiments that dynamically graft all model weights for a given position during generation. We call this “position grafting”. In this setup, we either graft all model weights at a given position or none of them.
First, we note that it’s not obvious that dynamic weight grafting will even work at all. It’s possible that representations and mechanisms drift enough during finetuning that grafting parameters between models results in nonsensical completions or completely fails to behave as one might expect. This is not what we see!
Instead, we see that grafting all model parameters at the first entity and the last token results in nearly recovering full finetuning performance.
Interestingly, we also see that, in some cases, grafting only at the first entity or only at the last token is sufficient to recover good relation completion performance. This implies two things:
- If an entity is “enriched” with relation information, generic mechanisms can extract the correct entity to complete the relation tuple.
- “Recall” mechanisms can extract relation completions from entities that were not enriched with finetuned relation information.
Both pathways together nearly recover full finetuning performance, and grafting everything except these pathways results in near-zero relation completion accuracy. Dynamic weight grafting allows us to show that the enrichment and recall pathways are necessary and sufficient for relation completion.
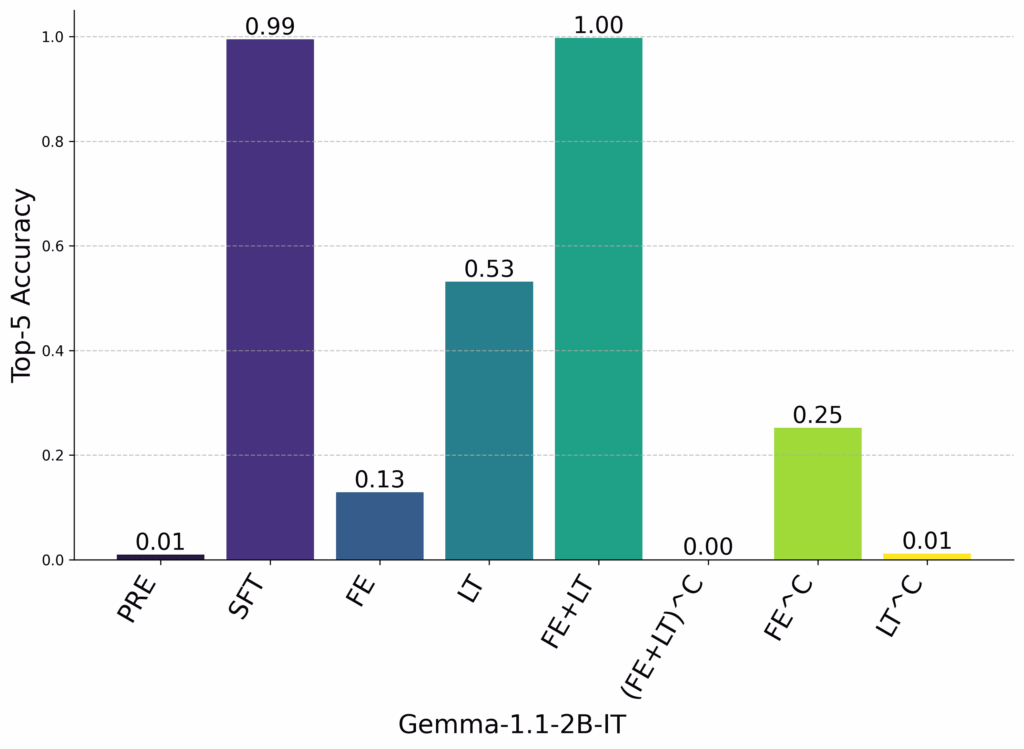
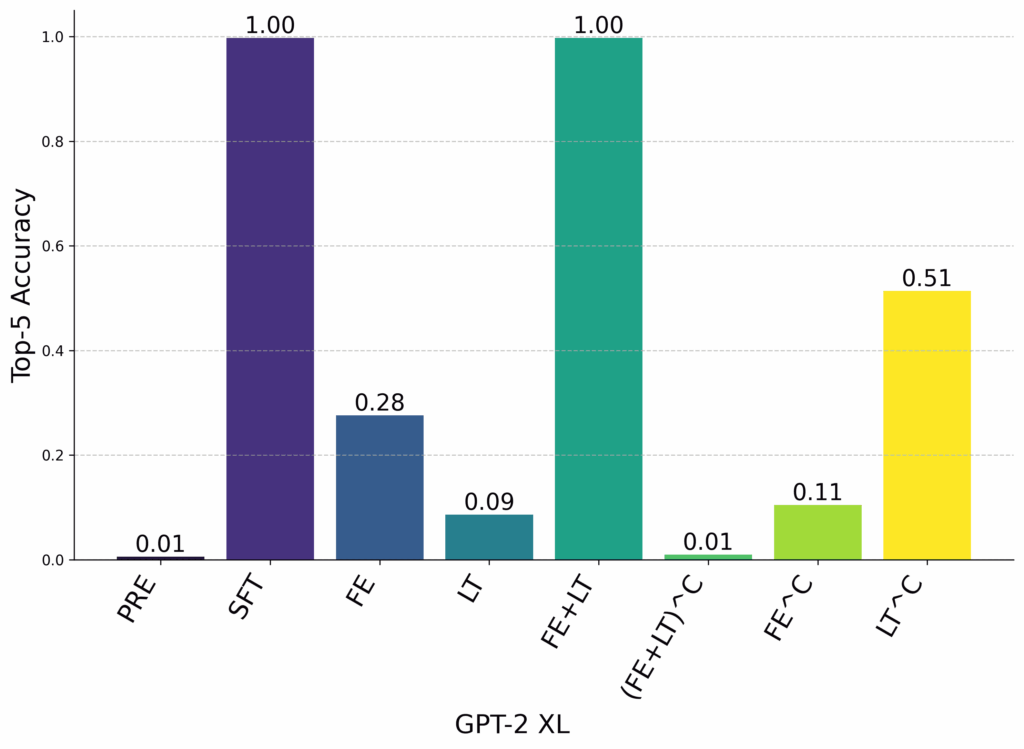
Results for Gemma and GPT-2 XL for position grafting. PRE is the pretrained model, SFT is the full finetuned model. FE is grafting only at the first entity token positions. LT is grafting only at the last token position. (FE+LT)^C is grafting at all token positions other than the first entity and the last token.
Localizing the “Recall” Mechanism
We seek to understand whether the “recall” pathway at the final token position relies mostly on attention, feedforward networks, or both.
To test this, we attempt to localize relation completion by training two separate models: one is a relation model trained on the full dataset; the other is a task model trained on text with the same semantic and syntactic structure but without the specific relation information we are attempting to retrieve.
We graft from the relation model to the task model at the final token position to examine the “recall” pathway. We see that grafting the Output Projection (O) matrix and the full FFN nearly recovers the results of grafting the full attention mechanism and the full FFN. This implies that, during finetuning, models learn operations in the O matrix that trigger the correct “recall” mechanism using FFNs in the final layers before predicting the recalled entity.
We were also surprised by the importance of the O matrix — removing the O matrix and using only the FFN harms top-5 accuracy by 29% in Gemma and 41% in Llama3.
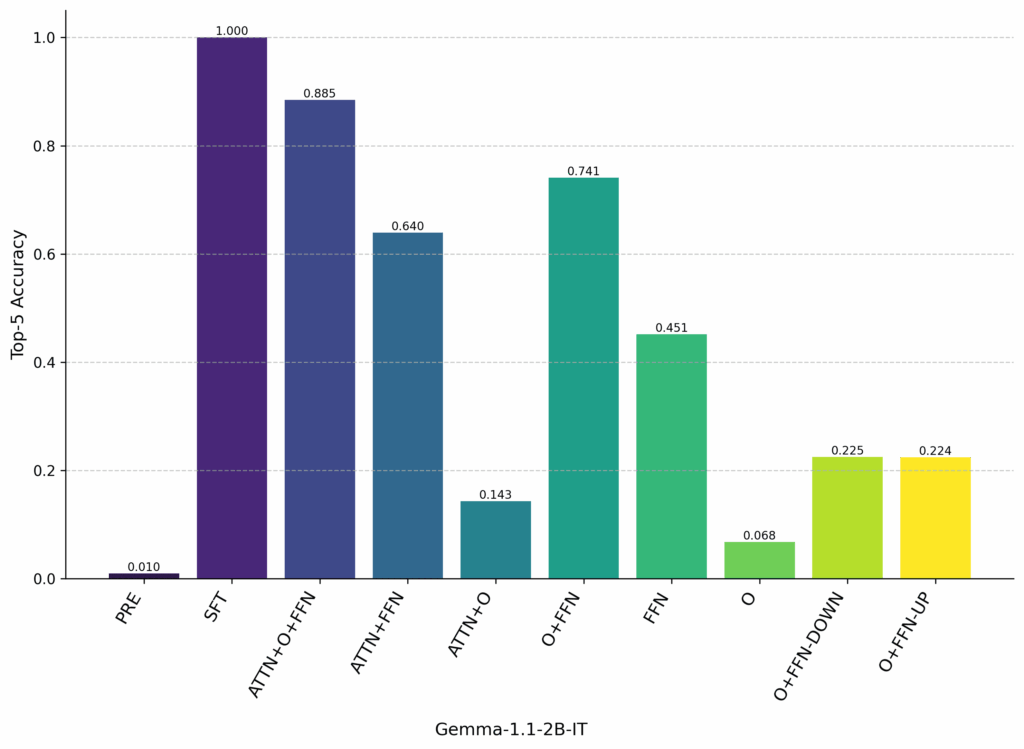
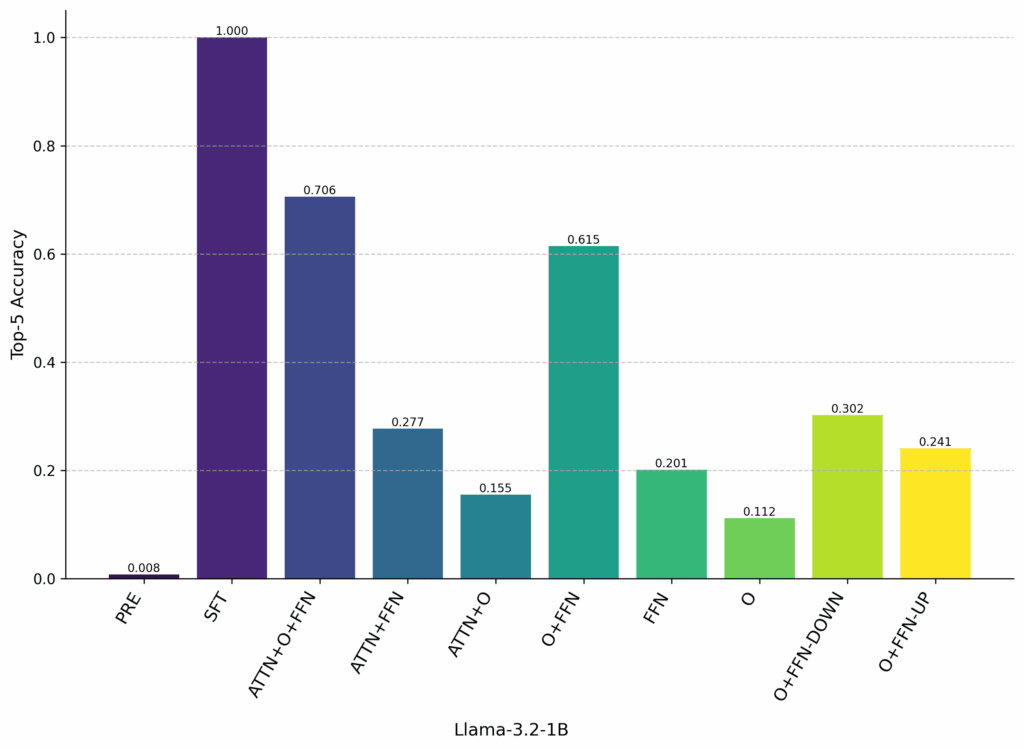
Component-grafting results for Gemma and Llama3 show that, for the “recall” pathway, models retrieve factual knowledge in the FFNs in the final layers before next token prediction. The output projection matrix, however, is also needed to get good performance and nearly recovers the same level of performance as grafting the full attention mechanism.
Do the Results Hold for Real Data?
We also explore whether these mechanisms apply to non-templated data. In these experiments, we finetune Gemma on twenty Wikipedia articles (and five LLM-generated rephrases for each article) about movies released after the model’s release date. This setting includes potential confounds (models are sensitive to the semantic structure of the finetuning data, the order that entities appear in, etc. — it’s also possible that information about some of these films was in the finetuning data even though the release date is after the model was released).
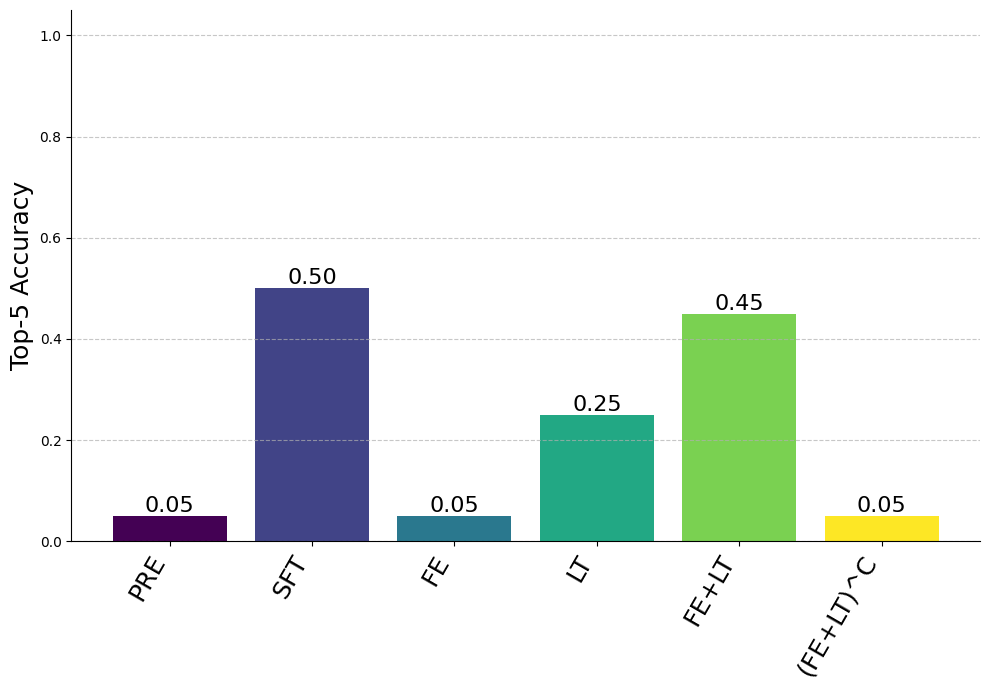
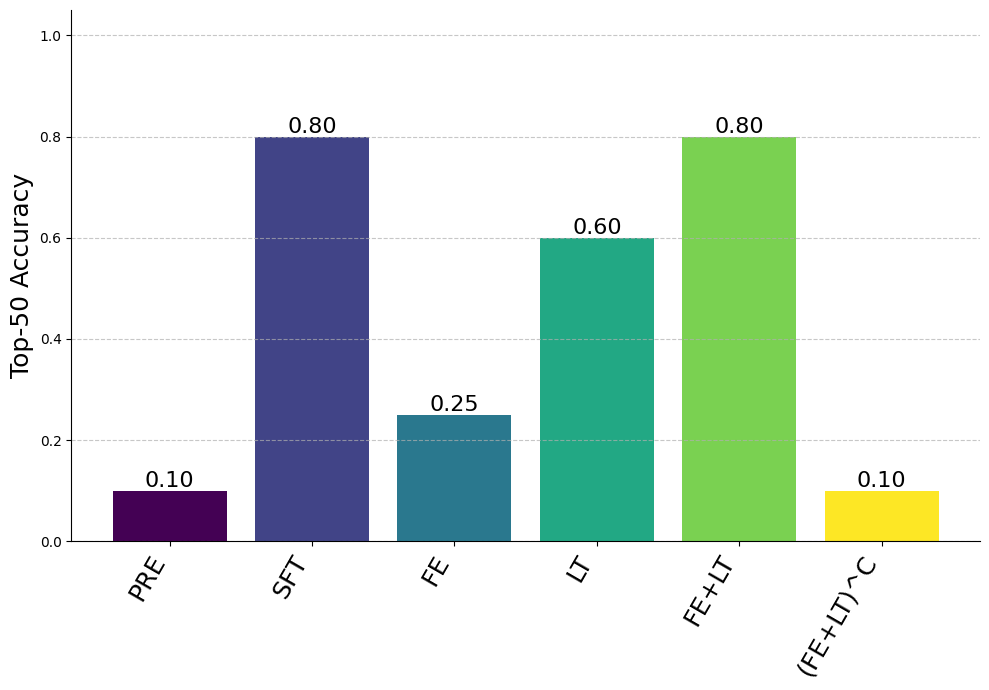
Still, we see the first entity and last token positions nearly recover full finetuning performance, the enrichment and recall pathways recover some finetuning performance (weaker in this setting than in the synthetic setting), and the complement of the first entity and the last token perform the same as the pretrained model. Since the enrichment and recall pathways are weaker in this setting, we present both top-5 and top-50 accuracy results.
Conclusion
- Dynamic weight grafting is a new technique that allows localization of finetuned model behavior to specific token positions and model components
- Using dynamic weight grafting, we show that models retrieve single-hop relation information using two pathways: “enrichment” on the first entity and “recall” at the last token before generation. At least one of these pathways is necessary for knowledge retrieval, both together nearly recover full finetuning performance.
- We localize the recall pathway to the output projection matrix and the feedforward networks in the final layers of the model.
- Our results hold for non-templated data: we see the same pattern with the enrichment and recall pathways (albeit weaker) when models are finetuned on Wikipedia articles for movies released after the model’s release date.
References
- L. Berglund, M. Tong, M. Kaufmann, M. Balesni, A. C. Stickland, T. Korbak, and O. Evans. The reversal curse: LLMs trained on “a is b” fail to learn “b is a”. arXiv preprint arXiv:2309.12288, 2023.
- M. Geva, J. Bastings, K. Filippova, and A. Globerson. Dissecting recall of factual associations in auto-regressive language models. arXiv preprint arXiv:2304.14767, 2023.
- E. Hernandez, A. S. Sharma, T. Haklay, K. Meng, M. Wattenberg, J. Andreas, Y. Belinkov, and D. Bau. Linearity of relation decoding in transformer language models. arXiv preprint arXiv:2308.09124, 2023.
- K. Meng, D. Bau, A. Andonian, and Y. Belinkov. Locating and editing factual associations in GPT. Advances in Neural Information Processing Systems, 35:17359–17372, 2022.
- J. Merullo, C. Eickhoff, and E. Pavlick. Language models implement simple word2vec-style vector arithmetic. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 5030–5047, 2024.
- A. Panigrahi, N. Saunshi, H. Zhao, and S. Arora. Task-specific skill localization in fine-tuned language models. International Conference on Machine Learning (ICML), pages 27011–27033, 2023.